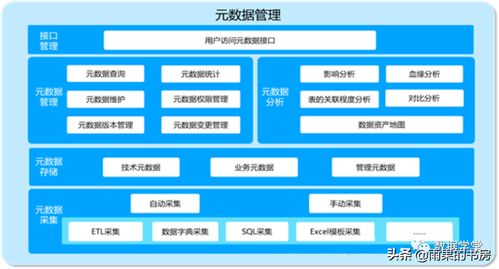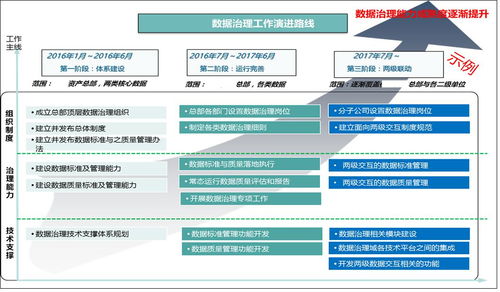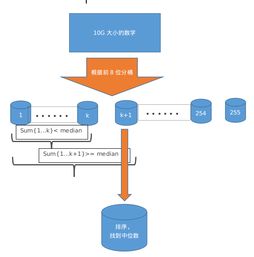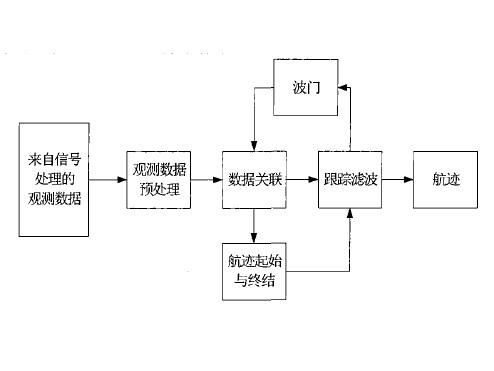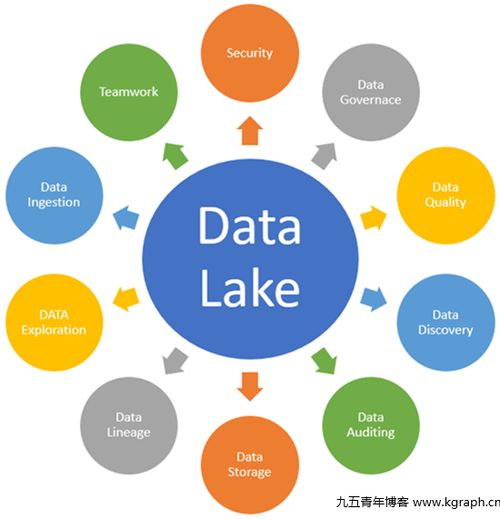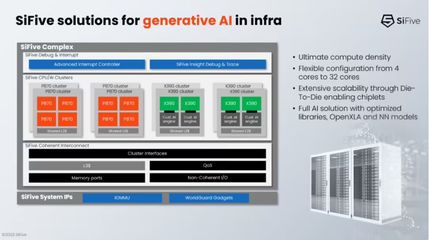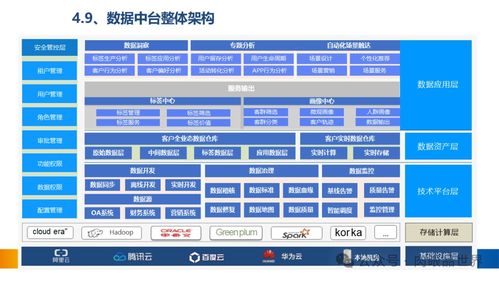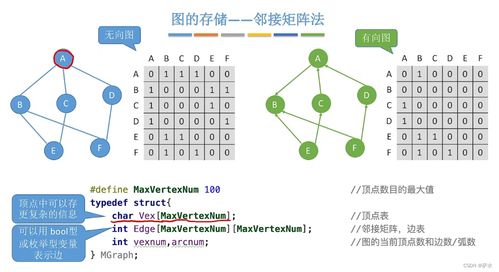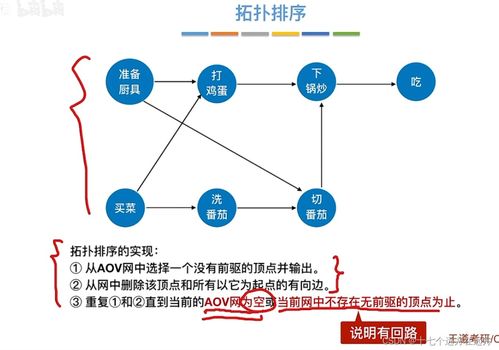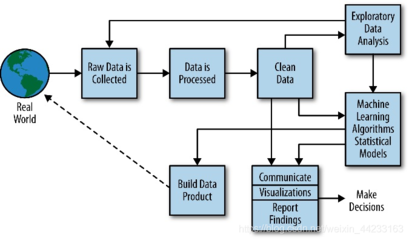
數(shù)據(jù)處理在大數(shù)據(jù)學(xué)習(xí)中扮演著至關(guān)重要的角色。它涉及從原始數(shù)據(jù)中提取有價值信息的全過程,包括數(shù)據(jù)采集、清洗、轉(zhuǎn)換、存儲和分析。隨著大數(shù)據(jù)技術(shù)的快速發(fā)展,數(shù)據(jù)處理的方法和工具也在不斷創(chuàng)新。
數(shù)據(jù)采集是數(shù)據(jù)處理的第一步。通過傳感器、日志文件、數(shù)據(jù)庫和互聯(lián)網(wǎng)等多種渠道,我們可以獲取海量數(shù)據(jù)。例如,企業(yè)通過用戶行為日志收集用戶偏好數(shù)據(jù),為后續(xù)分析奠定基礎(chǔ)。
數(shù)據(jù)清洗是確保數(shù)據(jù)質(zhì)量的關(guān)鍵環(huán)節(jié)。原始數(shù)據(jù)往往包含重復(fù)值、缺失值和異常值,需要通過工具如Python的Pandas庫或Apache Spark進(jìn)行清理。例如,在電商數(shù)據(jù)分析中,清洗掉無效的訂單記錄可以提升銷售預(yù)測的準(zhǔn)確性。
數(shù)據(jù)轉(zhuǎn)換則涉及將數(shù)據(jù)標(biāo)準(zhǔn)化、聚合或特征工程,以適配分析需求。常見技術(shù)包括使用SQL進(jìn)行數(shù)據(jù)匯總,或通過機(jī)器學(xué)習(xí)算法構(gòu)建特征。例如,在金融風(fēng)控中,將用戶交易數(shù)據(jù)轉(zhuǎn)換為風(fēng)險評分,有助于識別潛在欺詐行為。
數(shù)據(jù)存儲方面,分布式系統(tǒng)如Hadoop HDFS和云數(shù)據(jù)庫(如AWS S3)提供了可擴(kuò)展的解決方案。這些技術(shù)能夠處理TB級甚至PB級數(shù)據(jù),支持高效查詢和備份。
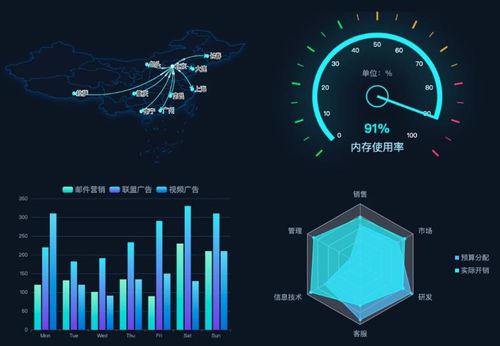
數(shù)據(jù)分析是數(shù)據(jù)處理的最終目標(biāo)。通過可視化工具(如Tableau)或高級分析(如預(yù)測建模),企業(yè)可以從數(shù)據(jù)中洞察趨勢,優(yōu)化決策。例如,醫(yī)療領(lǐng)域利用大數(shù)據(jù)分析疾病模式,推動精準(zhǔn)醫(yī)療發(fā)展。
數(shù)據(jù)處理是大數(shù)據(jù)學(xué)習(xí)的核心,掌握其流程和技術(shù),不僅能提升數(shù)據(jù)驅(qū)動決策的能力,還能在人工智能、物聯(lián)網(wǎng)等前沿領(lǐng)域發(fā)揮關(guān)鍵作用。持續(xù)學(xué)習(xí)和實(shí)踐是掌握數(shù)據(jù)處理技能的不二法門。